Cụm từ “ChatGPT” đang được rất nhiều người quan tâm và nghiên cứu nhưng có phải ai cũng biết rằng, ChatGPT trả lời được câu hỏi, là dựa trên phương pháp Machine learning và mô hình Deep learning hay không. Để hiểu rõ hơn về Machine learning cơ bản, bài viết dưới đây sẽ làm rõ câu hỏi Machine learning là gì? Mối quan hệ giữa Machine learning, Deep Learning và Neural Networks, cũng như cách hoạt động và ứng dụng của machine learning trong thực tế.
Machine learning là gì? Ứng dụng vào thực tế ra sao? (Nguồn: Interent)
Machine learning (học máy)là một nhánh của AI (trí tuệ nhân tạo) và khoa học máy tính, nó tập trung vào việc sử dụng dữ liệu và thuật toán để bắt chước cách học của con người, rồi dần dần cải thiện độ chính xác.
Machine learning cơ bản ra đời từ khi nào? IBM (International Business Machines) có một lịch sử phong phú với học máy. Một trong số đó, Arthur Samuel, được ghi nhận là người đã đặt ra thuật ngữ, “machine learning” với nghiên cứu của ông xung quanh trò chơi cờ caro.
Sau đó, Robert Nealey, bậc thầy cờ đam tự xưng, đã chơi trò chơi này trên máy tính IBM 7094 vào năm 1962 và ông đã thua máy tính. So với những gì làm được hiện nay, kỳ tích này có vẻ tầm thường, nhưng nó được coi là một cột mốc quan trọng trong lĩnh vực trí tuệ nhân tạo.
Trong vài thập kỷ qua, những tiến bộ công nghệ về khả năng lưu trữ và xử lý đã cho phép một số sản phẩm sáng tạo dựa trên machine learning, chẳng hạn như công cụ đề xuất của Netflix và ô tô tự lái.
Ngoài ra, Machine learning là gì ? Nó là một thành phần quan trọng trong lĩnh vực khoa học dữ liệu đang phát triển. Thông qua việc sử dụng các phương pháp thống kê, các thuật toán được đào tạo để phân loại hoặc dự đoán và khám phá những hiểu biết chính trong các dự án khai thác dữ liệu. Những thông tin chi tiết này sau đó sẽ thúc đẩy quá trình ra quyết định trong các ứng dụng và doanh nghiệp, tác động lớn đến các chỉ số tăng trưởng chính.
Khi dữ liệu lớn (big data) tiếp tục mở rộng và phát triển, nhu cầu thị trường đối với các nhà khoa học dữ liệu sẽ tăng lên. Họ sẽ được yêu cầu giúp xác định các câu hỏi kinh doanh phù hợp nhất và dữ liệu để trả lời chúng.
Các thuật toán machine learning cơ bản thường được tạo bằng cách sử dụng các khung tăng tốc phát triển giải pháp, chẳng hạn như TensorFlow và PyTorch.
Trí tuệ nhân tạo? Máy học là gì? Machine learning là gì? (Nguồn: Interent)
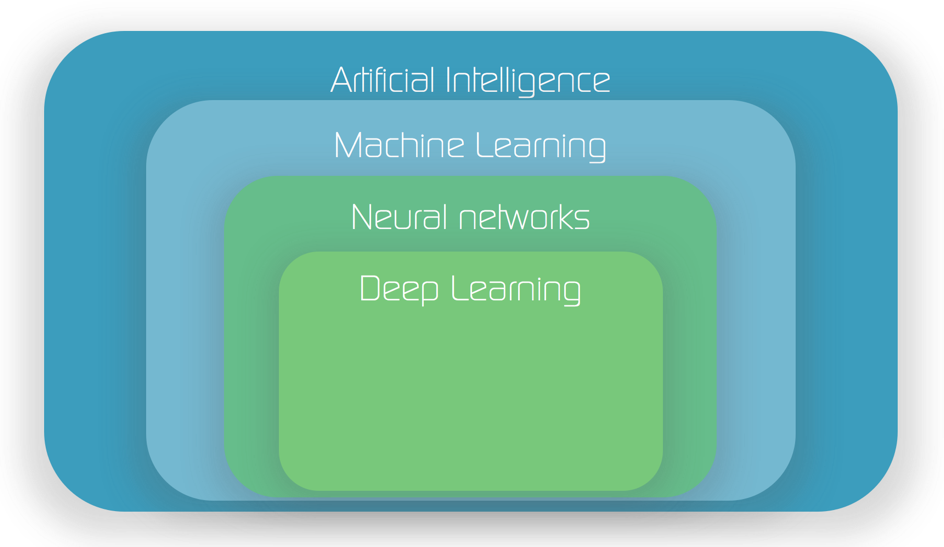
Mối liên hệ giữa Machine learning, Deep Learning và Neural Networks
Vì deep learning (học sâu) và machine learning có xu hướng được sử dụng thay thế cho nhau, nên cần lưu ý đến các sắc thái giữa hai loại này. Machine learning, deep learning và neural network (mạng Nơ Ron nhân tạo) đều là các lĩnh vực phụ của trí tuệ nhân tạo.
Tuy nhiên, Deep learning là một lĩnh vực phụ của neural networks. Và neural networks thực sự là một lĩnh vực phụ của machine learning.
Machine learning là gì? Mối liên hệ giữa Machine learning, Deep Learning và Neural Networks (Nguồn Internet)
Deep learning và machine learning khác nhau ở cách mỗi thuật toán học. “Deep” machine learning có thể sử dụng tập dữ liệu được gắn nhãn, còn được gọi là học có giám sát, để cung cấp thông tin cho thuật toán của nó nhưng không nhất thiết phải có tập dữ liệu được gắn nhãn. Còn Deep learning có thể nhập dữ liệu phi cấu trúc ở dạng thô (ví dụ: văn bản hoặc hình ảnh) và nó có thể tự động xác định tập hợp các tính năng phân biệt các loại dữ liệu khác nhau với nhau. Điều này giúp loại bỏ một số sự can thiệp bắt buộc của con người và cho phép sử dụng các tập dữ liệu lớn hơn
Classical, hoặc “non-deep”, machine learning cơ bản phụ thuộc nhiều hơn vào sự can thiệp của con người để học. Các chuyên gia về con người xác định tập hợp các tính năng để hiểu sự khác biệt giữa các đầu vào dữ liệu, thường yêu cầu dữ liệu có cấu trúc hơn để tìm hiểu.
Mạng nơ-ron hoặc mạng nơ-ron nhân tạo (ANN) bao gồm các lớp nút, chứa lớp đầu vào, một hoặc nhiều lớp ẩn và lớp đầu ra. Mỗi nút, hoặc nơ-ron nhân tạo, kết nối với nút khác, có trọng số và ngưỡng liên quan. Nếu đầu ra của bất kỳ nút riêng lẻ nào cao hơn giá trị ngưỡng đã chỉ định, nút đó sẽ được kích hoạt, gửi dữ liệu đến lớp tiếp theo của mạng. Mặt khác, nếu thấp hơn thì sẽ không có dữ liệu nào được chuyển đến lớp tiếp theo của mạng bởi nút đó. “Deep” in deep learning chỉ đề cập đến số lớp trong neural network (mạng nơ-ron). Một mạng nơ-ron bao gồm nhiều hơn ba lớp (bao gồm đầu vào và đầu ra) có thể được coi là một thuật toán deep learning hoặc deep neural network. Một neural network có ba lớp chỉ là một neural network cơ bản.
Deep learning và neural network được cho là đã đẩy nhanh tiến độ trong các lĩnh vực như thị giác máy tính, xử lý ngôn ngữ tự nhiên và nhận dạng giọng nói.
Cách machine learning hoạt động
Hệ thống học của thuật toán học máy gồm thành ba phần chính.
Quy trình quyết định: Nói chung, các thuật toán máy học được sử dụng để đưa ra dự đoán hoặc phân loại. Dựa trên một số dữ liệu đầu vào, có thể được gắn nhãn hoặc không gắn nhãn, thuật toán sẽ đưa ra ước tính về một mẫu trong dữ liệu.
Hàm lỗi: Hàm lỗi đánh giá dự đoán của mô hình. Nếu có các ví dụ đã biết, một hàm lỗi có thể so sánh để đánh giá độ chính xác của mô hình.
Quy trình tối ưu hóa mô hình: Nếu mô hình có thể phù hợp hơn với các điểm dữ liệu trong tập huấn luyện, thì các trọng số sẽ được điều chỉnh để giảm sự khác biệt giữa ví dụ đã biết và ước tính mô hình. Thuật toán sẽ lặp lại quy trình “đánh giá và tối ưu hóa” này, cập nhật trọng số một cách tự động cho đến khi đạt đến ngưỡng chính xác.
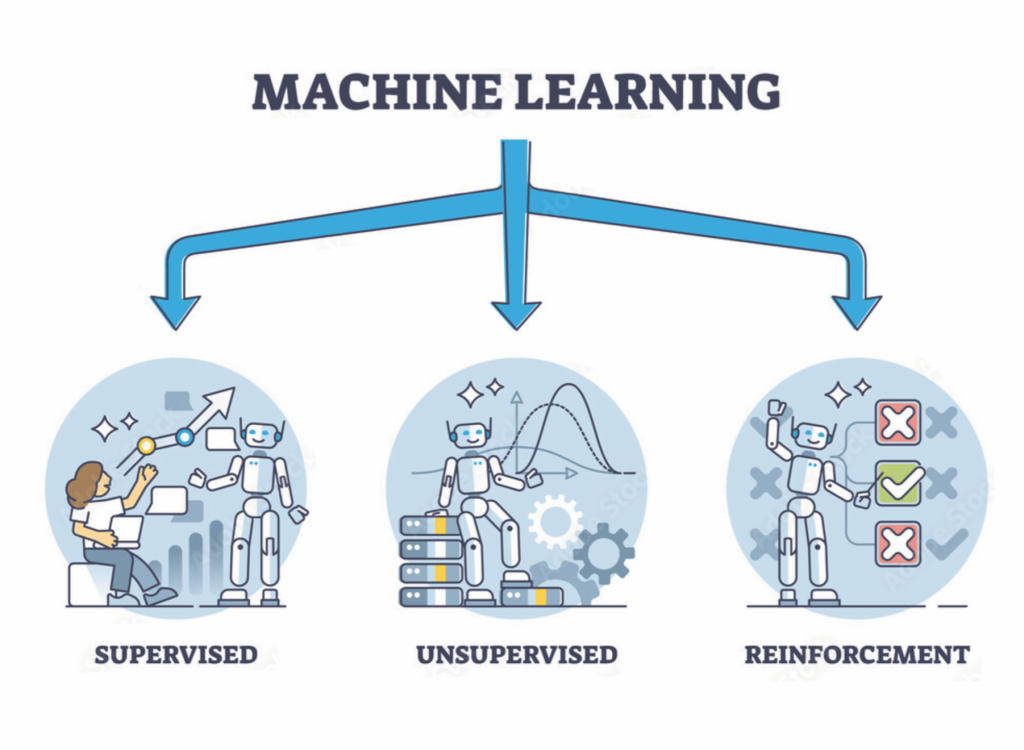
Mô hình machine learning cơ bản được chia thành các loại.
Machine learning là gì? Các phương pháp machine learning (Nguồn Internet)
Supervised machine learning
Supervised learning, còn được gọi là Supervised machine learning(học máy có giám sát), được xác định bằng cách sử dụng các bộ dữ liệu được gắn nhãn để huấn luyện các thuật toán nhằm phân loại dữ liệu hoặc dự đoán kết quả một cách chính xác.
Khi dữ liệu đầu vào được đưa vào mô hình, mô hình sẽ điều chỉnh trọng số của nó cho đến khi nó được điều chỉnh phù hợp. Điều này xảy ra như một phần của quy trình xác thực chéo để đảm bảo rằng mô hình tránh trang bị thừa hoặc thiếu. Learning có giám sát giúp các tổ chức giải quyết nhiều vấn đề trong thế giới thực ở quy mô lớn, chẳng hạn như phân loại thư rác trong một thư mục riêng biệt với hộp thư đến của bạn. Một số phương pháp được sử dụng trong học có giám sát bao gồm neural networks, naive bayes, hồi quy tuyến tính, hồi quy logistic, random forest và máy vector hỗ trợ (SVM).
Unsupervised machine learning
Unsupervised learning còn được gọi là Unsupervised machine learning (học máy không giám sát), sử dụng các thuật toán machine learning để phân tích và phân cụm các bộ dữ liệu không được gắn nhãn. Các thuật toán này khám phá các mẫu hoặc nhóm dữ liệu ẩn mà không cần sự can thiệp của con người.
Khả năng khám phá những điểm tương đồng và khác biệt trong thông tin của phương pháp này khiến nó trở nên lý tưởng cho việc phân tích dữ liệu khám phá, chiến lược cross-selling, phân khúc khách hàng cũng như nhận dạng hình ảnh và mẫu. Nó cũng được sử dụng để giảm số lượng các tính năng trong một mô hình thông qua quá trình giảm kích thước. Phân tích thành phần chính (PCA) và phân tích giá trị đơn lẻ (SVD) là hai cách tiếp cận phổ biến cho việc này. Các thuật toán khác được sử dụng trong học tập không giám sát bao gồm neural networks, phương pháp phân cụm k-means và phương pháp phân cụm xác suất.
Semi-supervised learning
Semi-supervised learning (học máy bán giám sát) cung cấp một phương tiện vui vẻ giữa học có giám sát và không giám sát. Trong quá trình đào tạo, nó sử dụng tập dữ liệu được gắn nhãn nhỏ hơn để hướng dẫn phân loại và trích xuất tính năng từ tập dữ liệu lớn hơn, không được gắn nhãn.
Học máy bán giám sát có thể giải quyết vấn đề không có đủ dữ liệu được gán nhãn cho thuật toán học có giám sát. Nó cũng hữu ích nếu việc dán nhãn đủ dữ liệu quá tốn kém.
Reinforcement machine learning
Reinforcement machine learning (Machine learning tăng cường) là một mô hình machine learning tương tự như learning có giám sát, nhưng thuật toán không được đào tạo bằng dữ liệu mẫu. Mô hình này học hỏi bằng cách sử dụng thử và sai. Một chuỗi các kết quả thành công sẽ được củng cố để phát triển khuyến nghị hoặc chính sách tốt nhất cho một vấn đề nhất định.
Machine learning là gì? Phân biệt giữa Supervised machine learning và Unsupervised machine learning (Nguồn: Interent)
Machine learning là gì? Một số thuật toán machine learning thường được sử dụng. Bao gồm các:
Neural networks: Mô phỏng cách thức hoạt động của bộ não con người, với một số lượng lớn các nút xử lý được liên kết. Mạng nơ-ron rất tốt trong việc nhận dạng các mẫu và đóng vai trò quan trọng trong các ứng dụng bao gồm dịch ngôn ngữ tự nhiên, nhận dạng hình ảnh, nhận dạng giọng nói và tạo hình ảnh.
Hồi quy tuyến tính: Thuật toán này được sử dụng để dự đoán các giá trị số, dựa trên mối quan hệ tuyến tính giữa các giá trị khác nhau. Ví dụ, kỹ thuật này có thể được sử dụng để dự đoán giá nhà dựa trên dữ liệu lịch sử của khu vực.
Hồi quy logistic: Thuật toán học có giám sát này đưa ra dự đoán cho các biến phản hồi phân loại, chẳng hạn như câu trả lời “có/không” cho các câu hỏi. Nó có thể được sử dụng cho các ứng dụng như phân loại thư rác và kiểm soát chất lượng trên dây chuyền sản xuất.
Phân cụm: Sử dụng phương pháp học không giám sát, các thuật toán phân cụm có thể xác định các mẫu trong dữ liệu để có thể nhóm lại. Máy tính có thể giúp các nhà khoa học dữ liệu bằng cách xác định sự khác biệt giữa các mục dữ liệu mà con người đã bỏ qua.
Decision trees(cây quyết định): Có thể được sử dụng cho cả dự đoán giá trị số (hồi quy) và phân loại dữ liệu thành các danh mục. Cây quyết định sử dụng một chuỗi phân nhánh của các quyết định được liên kết có thể được biểu diễn bằng sơ đồ cây. Một trong những ưu điểm của cây quyết định là chúng dễ dàng xác thực và kiểm toán, không giống như hộp đen của neural networks.
Random forests (rừng ngẫu nhiên): Trong một random forests, thuật toán machine learning dự đoán một giá trị hoặc danh mục bằng cách kết hợp các kết quả từ một số cây quyết định.
Bên cạnh đó, cũng cần quan tâm đến machine learning workflow (quy trình làm việc với Machine learning) để hoàn thành công việc nhanh chóng, đạt hiệu quả cao, hạn chế sai sót, tiết kiệm thời gian và nâng cao chất lượng toàn diện.
Machine learning workflow
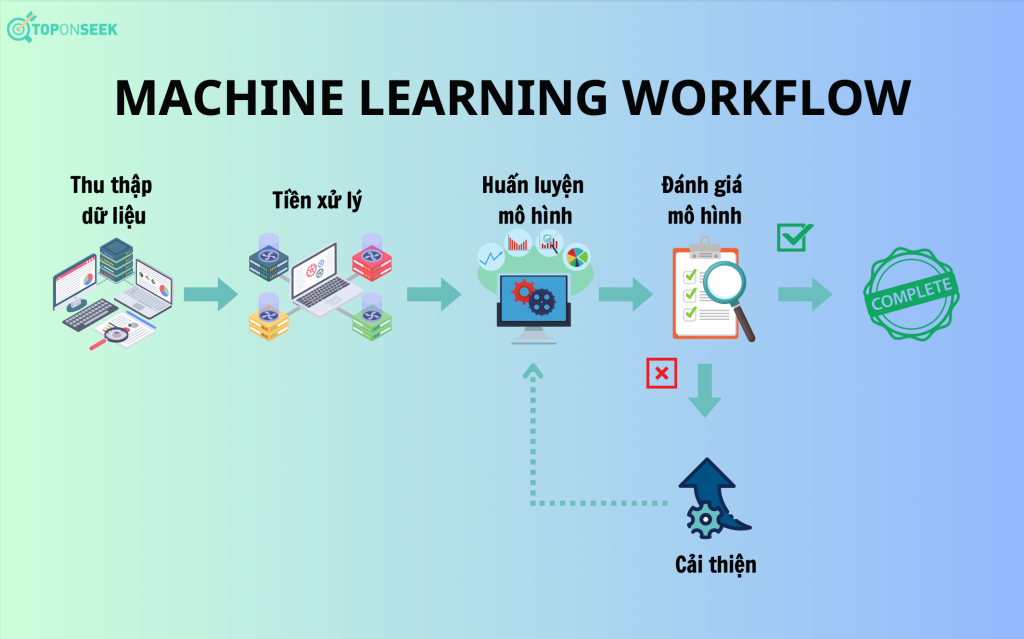
Machine learning workflow (Quy trình công việc học máy) xác định các bước làm việc cụ thể trong quá trình triển khai máy học. Tuy nhiên, tuỳ theo mỗi yêu cầu, mỗi dự án mà có những quy trình công việc học máy khác nhau, nhưng thường bao gồm 5 bước cơ bản sau:
5 bước cơ bản của Machine Learning Workflow (Nguồn: Interent)
Bước 1: Gathering machine learning data (Thu thập dữ liệu)
Quá trình này phụ thuộc vào dự án và loại dữ liệu bạn cần. Có thể là dữ liệu thời gian thực hoặc là dữ liệu tĩnh từ cơ sở dữ liệu hiện có.
Lập trình viên cần cung cấp bộ dữ liệu (dataset) cho máy để máy tính có thể học, phân tính và đưa ra phán đoán phục vụ cho mục đích sử dụng.
Chú ý lựa chọn bộ dữ liệu cần có tính xác thực, từ các nguồn chính thống thì máy tính mới có thể học một cách chính xác, đưa ra được kết quả đúng và tăng tính hiệu quả cho dự án.
Bước 2: Data pre-processing (Tiền xử lý dữ liệu)
Bước này giúp bạn chuẩn hoá bộ dữ liệu đã thu thập được. Sau đó, loại bỏ các thuộc tính không cần thiết, loại bỏ các yếu tố thiếu hoặc nhiễu. Đồng thời, thực hiện gán nhãn dữ liệu, mã hóa một số đặc trưng, trích xuất các đặc trưng, rút gọn dữ liệu mà vẫn đảm bảo kết quả đầu ra.
Đây là bước tốn nhiều thời gian nhất, bước 1 và bước 2 chiếm đến khoảng 70% thời gian của cả quy trình. Do đó, bước này rất quan trọng vì nó quyết định đến sự thành công và tính hiệu quả của cả quy trình.
Bước 3: Training model (Huấn luyện mô hình)
Ở bước này, máy tính sẽ học và tiến hành xử lý từ dữ liệu đã cung cấp ở 2 bước trên, bằng cách kết nối dataset với một thuật toán. Tiếp đến, thuật toán sẽ tận dụng mô hình toán học phức tạp để tìm hiểu và phát triển các dự đoán.
Thuật toán được sử dụng sẽ rơi vào 3 loại
Nhị phân
Phân loại
Hồi quy
Bước 4: Evaluating model (đánh giá mô hình)
Bước này sẽ đánh giá, kiểm tra độ chính xác của mô hình vừa tạo ra. Quá trình này sẽ dựa vào từng loại độ đo khác nhau để đánh giá độ tốt xấu nên sẽ không có quy chuẩn cụ thể. Nhưng về cơ bản, độ chính xác của mô hình vừa huấn luyện đạt trên 80% thì được coi là có hiệu quả.
Bước 5: Improve (cải thiện)
Nếu kết quả từ bước đánh giá mô hình không khả quan thì machine learning phải được huấn luyện lại. Ta sẽ lặp lại bước 3, bước 4 cho đến khi đạt được độ chính xác như kỳ vọng.
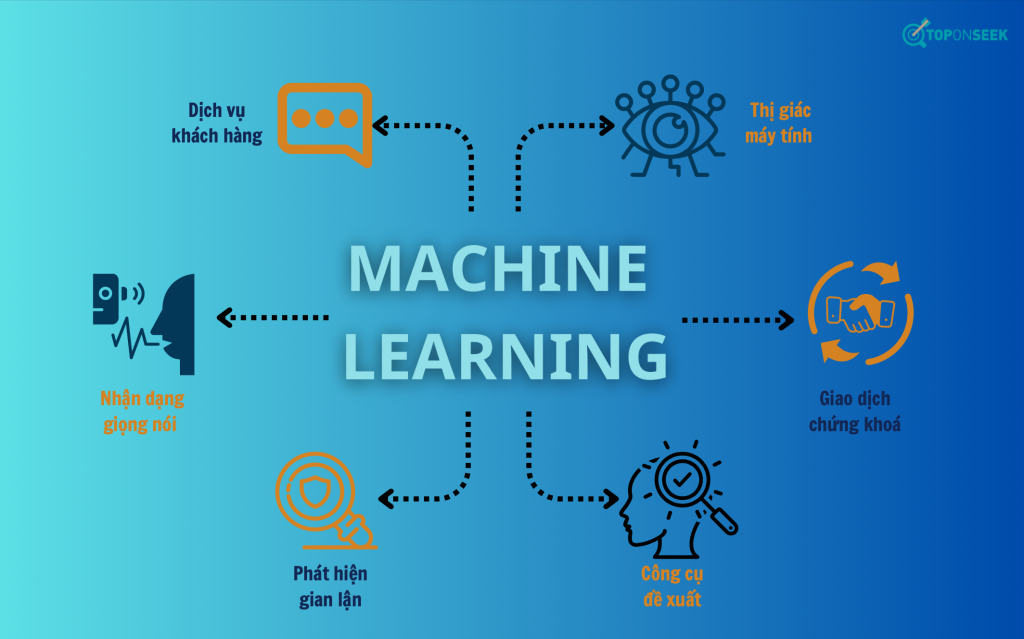
Top 6 ứng dụng thực tế phổ biến nhất của machine learning
Một vài ví dụ về machine learning là gì mà bạn có thể gặp hàng ngày:
1. Nhận dạng giọng nói
Nhận dạng giọng nói có 2 thuật ngữ là Voice recognition và Speech recognition
Speech recognition tập trung vào việc nhận dạng từ ngữ và chuyển các từ ngữ này sang dạng văn bản. Đây là khả năng sử dụng quá trình xử lý ngôn ngữ tự nhiên (NLP) để dịch lời nói của con người sang định dạng viết. Voice recognition có khả năng nhận dạng và định danh giọng nói của từng người dùng, nhờ sự ra đời của Deep Learning.
Nhận diện giọng nói được ứng dụng trong
Tối ưu việc nhập liệu: tiết kiệm được thời gian nhập văn bản
Điều khiển nhà thông minh (smarthome): chỉ bằng giọng nói có thể tắt/bật điện, tắt/mở điều hoà hoặc kéo/đóng rèm cửa)
Lập trình trợ lý ảo: nhiều thiết bị di động kết hợp nhận dạng giọng nói vào hệ thống của họ, để tiến hành tìm kiếm bằng giọng nói, ví dụ: trợ lý ảo Siri của Apple, Google Assistant – trợ lý ảo của Google, Alexa của Amazon
2. Dịch vụ khách hàng(Customer service)
Các chatbot trực tuyến đang thay thế các đại lý con người trong suốt hành trình của khách hàng, thay đổi cách chúng ta nghĩ về sự tương tác của khách hàng trên các trang web và nền tảng truyền thông xã hội. Chatbot trả lời các câu hỏi thường gặp (FAQ) về các chủ đề như vận chuyển hoặc cung cấp lời khuyên được cá nhân hóa, bán chéo sản phẩm hoặc đề xuất kích thước cho người dùng.
Ví dụ như đại lý ảo trên các trang web thương mại điện tử; bot nhắn tin, sử dụng Slack và Facebook Messenger; và các tác vụ thường được thực hiện bởi trợ lý ảo và trợ lý giọng nói.
3. Thị giác máy tính(Computer vision)
Công nghệ AI này cho phép máy tính lấy thông tin có ý nghĩa từ hình ảnh kỹ thuật số, video và các đầu vào trực quan khác, sau đó thực hiện hành động thích hợp.
Được hỗ trợ bởi convolutional neural networks, thị giác máy tính có các ứng dụng trong việc
Gắn thẻ ảnh trên phương tiện truyền thông xã hội như là Facebook
Chụp ảnh X quang trong chăm sóc sức khỏe và
Ô tô tự lái trong ngành công nghiệp ô tô
4. Công cụ đề xuất(Recommendation engines)
Sử dụng dữ liệu hành vi tiêu dùng trong quá khứ, thuật toán AI giúp khám phá các xu hướng dữ liệu có thể được sử dụng để phát triển các chiến lược bán kèm hiệu quả hơn. Phương pháp này được các nhà bán lẻ trực tuyến sử dụng để đưa ra các đề xuất sản phẩm phù hợp cho khách hàng trong quá trình thanh toán.
5.Giao dịch chứng khoán tự động(Automated stock trading)
Được thiết kế để tối ưu hóa danh mục đầu tư chứng khoán, các nền tảng giao dịch tần suất cao do AI điều khiển thực hiện hàng nghìn, thậm chí hàng triệu giao dịch mỗi ngày mà không cần sự can thiệp của con người.
6. Phát hiện gian lận(Fraud detection)
Các ngân hàng và tổ chức tài chính khác đã sử dụng machine learning để phát hiện các giao dịch đáng ngờ. Learning có giám sát có thể đào tạo một mô hình bằng cách sử dụng thông tin về các giao dịch gian lận đã biết. Tính năng phát hiện bất thường có thể xác định các giao dịch có vẻ không điển hình và cần được điều tra thêm.
Top 6 ứng dụng của machine learning trong đời số thực tiễn (Nguồn: Interent)
Machine learning là gì? Những thách thức của machine learning
Khi công nghệ machine learning phát triển, chắc chắn nó đã làm cho cuộc sống của chúng ta dễ dàng hơn. Tuy nhiên, việc triển khai machine learning trong các doanh nghiệp cũng làm dấy lên một số lo ngại về đạo đức đối với công nghệ AI. Một số trong số này bao gồm:
Điểm kỳ dị công nghệ (Technological singularity)
Trong khi chủ đề này thu hút rất nhiều sự chú ý của công chúng, nhiều nhà nghiên cứu không quan tâm đến ý tưởng AI sẽ vượt qua trí thông minh của con người trong tương lai gần.
Điểm kỳ dị công nghệ còn được gọi là trí tuệ nhân tạo mạnh mẽ hoặc siêu trí tuệ. Triết gia Nick Bostrum định nghĩa siêu trí tuệ là “bất kỳ trí tuệ nào vượt trội hơn rất nhiều so với bộ não tốt nhất của con người trong thực tế mọi lĩnh vực, bao gồm khả năng sáng tạo khoa học, trí tuệ chung và kỹ năng xã hội”.
Mặc dù thực tế là trí tuệ siêu việt chưa xuất hiện trong xã hội, nhưng ý tưởng về nó đặt ra một số câu hỏi thú vị khi chúng ta xem xét việc sử dụng các hệ thống tự trị, chẳng hạn như ô tô tự lái.
Thật không thực tế khi nghĩ rằng một chiếc xe không người lái sẽ không bao giờ gặp tai nạn, nhưng ai chịu trách nhiệm và chịu trách nhiệm pháp lý trong những trường hợp đó? Chúng ta có nên tiếp tục phát triển các phương tiện tự trị hay chỉ giới hạn công nghệ này ở các phương tiện bán tự trị giúp mọi người lái xe an toàn? Vẫn chưa thể có câu trả lời chính xác vấn đề này, nhưng nó gây tranh luận về đạo đức và trách nhiệm xã hội khi mà công nghệ AI đang phát triển, đổi mới không ngừng.
AI tác động đến việc làm(AI impact on jobs)
Trong khi chúng ta đang lo ngại rằng trí tuệ nhân tạo sẽ gây ra tình trạng mất việc làm, thì có lẽ nên điều chỉnh lại suy nghĩ này.
Chỉ những công việc có tính lặp đi lặp lại cao hoặc dựa trên các hướng dẫn, quy định cụ thể sẽ là nhưng vị trí gặp nhiều rủi ro. Còn những công việc thường xuyên thay đổi, không ngừng cập nhập, đổi mới, yêu cầu sự linh hoạt và khả năng thích ứng cao thì sẽ rất khó bị thay thế.
Với mỗi công nghệ mới, mang tính đột phá, chúng ta thấy rằng nhu cầu thị trường đối với các vai trò công việc cụ thể sẽ thay đổi. Ví dụ, khi chúng ta xem xét ngành công nghiệp ô tô, nhiều nhà sản xuất, như GM, đang chuyển sang tập trung vào sản xuất xe điện để phù hợp với các sáng kiến xanh. Ngành năng lượng sẽ không biến mất, nhưng nguồn năng lượng đang chuyển từ tiết kiệm nhiên liệu sang sử dụng điện.
Theo cách tương tự, trí tuệ nhân tạo sẽ chuyển nhu cầu việc làm sang các lĩnh vực khác. Sẽ cần có những cá nhân giúp quản lý hệ thống AI. Sẽ vẫn cần có người giải quyết các vấn đề phức tạp hơn trong các ngành có nhiều khả năng bị ảnh hưởng bởi sự thay đổi nhu cầu việc làm, chẳng hạn như dịch vụ khách hàng. Thách thức lớn nhất với trí tuệ nhân tạo và ảnh hưởng của nó đối với thị trường việc làm sẽ là giúp mọi người chuyển đổi sang những vai trò mới đang được yêu cầu.
Sự riêng tư(Privacy)
Quyền riêng tư đề cập đến ở đây là quyền riêng tư dữ liệu, bảo vệ dữ liệu và bảo mật dữ liệu. Những mối quan tâm này đã cho phép các nhà hoạch định chính sách đạt được nhiều bước tiến hơn trong những năm gần đây.
Ví dụ: Vào năm 2016, luật GDPR đã được tạo ra để bảo vệ dữ liệu cá nhân của những người ở Liên minh Châu Âu và Khu vực Kinh tế Châu Âu, giúp các cá nhân có nhiều quyền kiểm soát hơn đối với dữ liệu của họ.
Tại Hoa Kỳ, các tiểu bang riêng lẻ đang xây dựng các chính sách, chẳng hạn như Đạo luật về quyền riêng tư của người tiêu dùng California (CCPA), được ban hành vào năm 2018 và yêu cầu các doanh nghiệp thông báo cho người tiêu dùng về việc thu thập dữ liệu của họ.
Những luật như thế này đã buộc các công ty phải suy nghĩ lại về cách họ lưu trữ và sử dụng thông tin nhận dạng cá nhân (PII). Do đó, các khoản đầu tư vào bảo mật ngày càng trở thành ưu tiên hàng đầu của các doanh nghiệp khi họ tìm cách loại bỏ mọi lỗ hổng và cơ hội để giám sát, hack và tấn công mạng.
Thiên vị và phân biệt đối xử(Bias and discrimination)
Các trường hợp thiên vị và phân biệt đối xử trong một số hệ thống máy học đã đặt ra nhiều câu hỏi về đạo đức liên quan đến việc sử dụng trí tuệ nhân tạo. Làm cách nào chúng ta có thể bảo vệ chống lại sự thiên vị và phân biệt đối xử khi chính dữ liệu đào tạo có thể được tạo ra bởi các quy trình thiên vị của con người?
Mặc dù các công ty thường có ý định tốt cho các nỗ lực tự động hóa của họ, nhưng Reuters (liên kết nằm bên ngoài IBM)) nêu bật một số hậu quả không lường trước được của việc kết hợp AI vào các hoạt động tuyển dụng. Trong nỗ lực tự động hóa và đơn giản hóa một quy trình, Amazon đã vô tình phân biệt đối xử với các ứng viên theo giới tính đối với các vị trí kỹ thuật và cuối cùng công ty đã phải hủy bỏ dự án. Harvard Business Review (liên kết nằm bên ngoài IBM) đã đặt ra những câu hỏi quan trọng khác về việc sử dụng AI trong thực tiễn tuyển dụng, chẳng hạn như dữ liệu nào bạn có thể sử dụng khi đánh giá ứng viên cho một vai trò.
Sự thiên vị và phân biệt đối xử cũng không giới hạn trong chức năng nguồn nhân lực; chúng có thể được tìm thấy trong một số ứng dụng từ phần mềm nhận dạng khuôn mặt đến các thuật toán truyền thông xã hội.
Khi các doanh nghiệp nhận thức rõ hơn về những rủi ro với AI, họ cũng trở nên tích cực hơn trong cuộc thảo luận này về các giá trị và đạo đức của AI. Ví dụ, IBM đã ngừng sản xuất các sản phẩm phân tích và nhận dạng khuôn mặt cho mục đích chung. Giám đốc điều hành IBM Arvind Krishna đã viết: “IBM kiên quyết phản đối và sẽ không tha thứ cho việc sử dụng bất kỳ công nghệ nào, kể cả công nghệ nhận dạng khuôn mặt do các nhà cung cấp khác cung cấp, để giám sát hàng loạt, lập hồ sơ chủng tộc, vi phạm các quyền và tự do cơ bản của con người hoặc bất kỳ mục đích nào không nhất quán. với các giá trị và Nguyên tắc Tin cậy và Minh bạch của chúng ta.”
Trách nhiệm giải trình(Accountability)
Vì không có luật quan trọng để điều chỉnh các hoạt động của AI, nên không có cơ chế thực thi nào thực sự để đảm bảo rằng AI có đạo đức được thực hành. Các khuyến khích hiện tại để các công ty trở nên có đạo đức là những hậu quả tiêu cực của một hệ thống AI phi đạo đức ở điểm mấu chốt. Để lấp đầy khoảng trống, các khuôn khổ đạo đức đã xuất hiện như một phần của sự hợp tác giữa các nhà đạo đức và nhà nghiên cứu để quản lý việc xây dựng và phân phối các mô hình AI trong xã hội.
Tuy nhiên, tại thời điểm này, những điều này chỉ phục vụ để hướng dẫn. Một số nghiên cứu cho thấy rằng sự kết hợp giữa trách nhiệm phân tán và việc thiếu tầm nhìn xa đối với các hậu quả có thể xảy ra không có lợi cho việc ngăn chặn tác hại đối với xã hội.
Tóm lại, trong thời đại 4.0, Machine Learning là một công cụ tuyệt vời cần được khai thác và ứng dụng vào trong nhiều lĩnh vực và ngành nghề. Với bài viết này TopOnSeek đã làm rõ được Machine Learning là gì, cách hoạt động cũng như ứng dụng của nó trong thực tế. Mong rằng bài viết sẽ đem lại thông tin hữu ích cho bạn.