Crawling là một trong những thuật ngữ cơ bản khi bạn bắt đầu tìm hiểu về SEO. Crawling là một quá trình giúp cho Google hiểu được nội dung trên website của bạn. Bài viết sau đây sẽ cho bạn biết rõ hơn Crawling là gì và tại sao nó quan trọng trong SEO.
Crawling (còn gọi là thu thập thông tin) là quá trình khám phá trong đó các công cụ tìm kiếm gửi ra một nhóm Googlebot (được gọi là trình thu thập thông tin hoặc trình thu thập dữ liệu) để tìm nội dung mới và cập nhật. Tuy nội dung có thể khác nhau ví dụ như trang web, hình ảnh, video, PDF,… nhưng bất kể ở định dạng nào thì chúng hầu hết được phát hiện bởi các liên kết.
SEO (Search Engine Optimization) là hoạt động tối ưu thứ hạng từ khóa (keyword ranking) của một ngành nghề, dịch vụ, sản phẩm,… trên các công cụ tìm kiếm. Vị trí càng cao sẽ có tỷ lệ khách hàng có khả năng vào trang web của bạn càng lớn.
Crawling rất quan trọng trong quá trình lập chỉ mục (index) các dữ liệu trên các trang web bằng cách sử dụng một chương trình tự động. Các chương trình tự động này được biết đến với nhiều tên gọi khác nhau như web crawler, spider, bot crawler hay ngắn gọn là crawler.
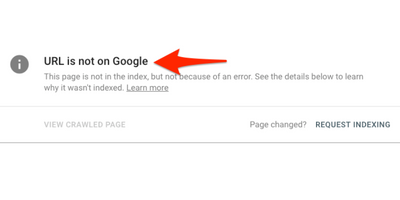
Web Crawler sẽ tải xuống các trang web để công cụ tìm kiếm xử lý, lập chỉ mục các trang web này để người dùng tìm kiếm hiệu quả hơn. Do đó người dùng có thể truy xuất bất kỳ thông tin nào trên một hoặc nhiều trang khi cần. Nếu dữ liệu từ trang web không được web crawler thu thập, nó sẽ không thể được (index). Điều đó đồng nghĩa với việc trang web không được hiển thị trong kết quả tìm kiếm. Người dùng cũng không thể tìm thấy trang web của bạn ngay cả khi nhập chính xác từng chữ được lấy trực tiếp từ trang web.
Tại sao Web Crawler lại quan trọng trong SEO? (Nguồn: Internet)
Web Crawler hoạt động như thế nào?
Web Crawler bắt đầu quá trình thu thập thông tin bằng cách tải xuống tệp robot.txt của trang web. Tệp này bao gồm sitemaps – các sơ đồ trang web liệt kê trong đó các URL mà công cụ tìm kiếm có thể thu thập. Để cố gắng tìm tất cả thông tin liên quan mà Internet phải cung cấp, một bot crawler sẽ bắt đầu với một tập hợp các trang web đã biết nhất định và sau đó theo các hyperlink từ các trang đó đến các trang khác. Các bots sẽ thêm các URL mới được phát hiện này vào hàng đợi để chúng có thể được index sau này. Nhờ vậy mà web crawler có thể lập chỉ mục mọi trang web được kết nối với những trang khác.
Nếu bạn có một trang web mới chưa có mạng lưới liên kết giữa các trang hoặc liên kết trang web của bạn với những người khác, bạn có thể yêu cầu lập chỉ mục trang web bằng cách gửi URL trên Google Search Console.
Các trang web luôn thay đổi và cập nhật nội dung thường xuyên, tuy nhiên web crawler không thu thập thông tin của toàn bộ internet. Thay vào đó, nó sẽ quyết định tầm quan trọng của mỗi trang web dựa trên các yếu tố bao gồm số lượng backlinks đến trang web đó, số lượt xem trang và thậm chí cả uy tín thương hiệu. Vì vậy, các bots sẽ xác định trang nào cần thu thập thông tin, thứ tự thu thập dữ liệu trang và tần suất thu thập thông tin để cập nhật.
Những Web Crawler nào đang hoạt động trên Internet?
Các công cụ tìm kiếm phổ biến đều có trình thu thập thông tin web riêng. Ví dụ: Google có trình thu thập thông tin chính là Googlebot, bao gồm thu thập dữ liệu trên thiết bị di động và máy tính để bàn. Nhưng cũng có một số bot bổ sung cho Google như Googlebot Images, Googlebot Videos, Googlebot News và AdsBot.
Những Web Crawler nào đang hoạt động trên Internet? (Nguồn: Internet)
Ngoài ra còn có nhiều bot crawler ít phổ biến hơn, dưới đây là một số web crawler khác mà bạn có thể bắt gặp:
Crawling là gì? Phân biệt Web Crawler và Web Scraper
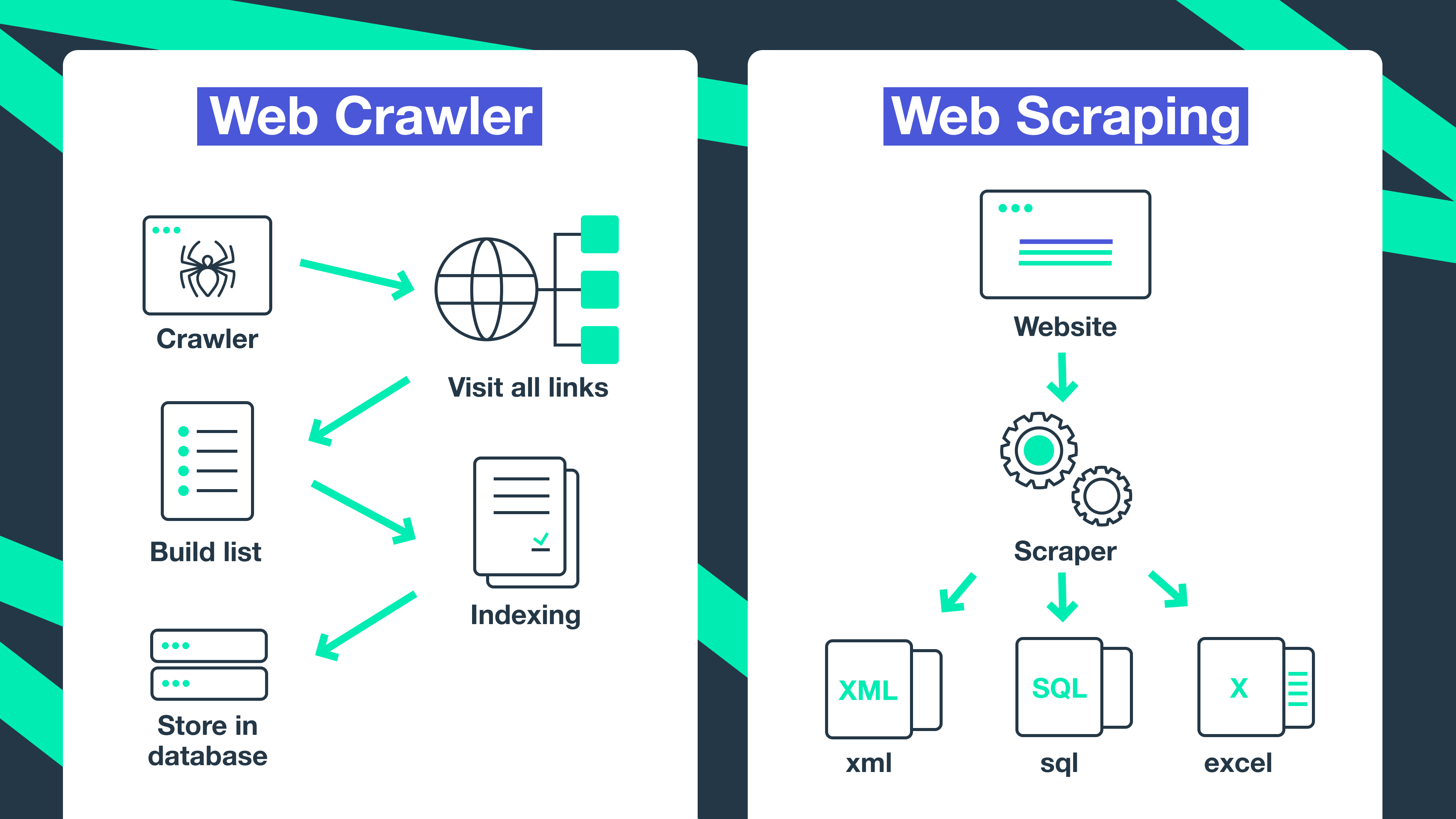
Hai thuật ngữ Web Scraper và Web Crawler có liên quan với nhau và thường bị nhiều người nhầm lẫn hoặc khó phân biệt bởi thường được sử dụng thay thế cho nhau. Tuy nhiên giữa chúng vẫn có những khác biệt nhất định.
Crawling là gì? Phân biệt Web Crawler và Web Scraper (Nguồn: Internet)
Scraping và Crawling vừa tương đồng vừa khác biệt
Web Crawler sẽ thu thập thông tin từ các website từ đường link cho trước, không chỉ thu thập toàn bộ thông tin của trang web mà còn truy cập thêm vào các link bên trong để tiếp tục thu thập dữ liệu. Mặt khác, Web Scraper tập trung thu thập một tập hợp dữ liệu cụ thể trên một trang web phù hợp với mục đích của người dùng, đó có thể là: chi tiết sản phẩm, bảng giá, review đánh giá,…
Scraping có thể thực hiện một cách thủ công để thu thập thông tin cần thiết, theo mục đích tìm kiếm hoặc cũng có thể thực hiện bằng các công cụ tự động. Còn Crawling chỉ có thể được thực hiện với công cụ thu thập thông tin tự động là một bot crawler.
Hy vọng qua bài viết trên đã giúp bạn hiểu được Crawling là gì cũng như cách thức hoạt động của Web Crawler đóng vai trò quan trọng trong SEO. Nếu bạn muốn có thêm kiến thức về SEO thì hãy tham khảo ngay các bài blog đầy chất lượng và bổ ích của TopOnSeek ngay hôm nay.